Foreword
网络厂商提供的平台级流量监控方案通常要么与自家生态深度绑定;要么缺少开放接口,数据难以与外部服务集成和流通,实际网络建设中我们经常混合使用多厂商的设备,这个事情就变得复杂了,最好寻求一些通用的指标采集方案。
对于接口和设备粒度下的流量监控,有成熟的SNMP协议,对于Prometheus+Grafana生态来说,SNMP Exporter可以很好地采集这些指标。
对于更细粒度的三层报文采集,比如说应用层的流量分析,包括IP、协议、端口信息等,NetFlow和sFlow是目前主流的两种协议,其中NetFlow由思科创建和支持,在2003年,IETF组织确定NetFlow v9作为IPFIX标准的基础。sFlow在2001年由InMon公司、惠普(HP)和Foundry Networks三家公司联合开发,后来被IETF采纳为草拟标准RFC 3176,此外还有华为推出的NetStream,相关具体的支持情况还请参阅厂商的设备文档。
我的环境中主要是H3C的设备偏多,所以本文主要使用SNMP+sFlow实践,并分别与Grafana进行集成。
架构概览:
flowchart TD
subgraph "sFlow"
A[网络设备] -->|NetFlow/sFlow/IPFIX| B[Goflow2]
B -->|解析后数据| C[Kafka]
C -->|流数据| D[ClickHouse]
end
D -->|查询数据| E[Grafana]
subgraph "SNMP"
F[网络设备] -->|SNMP| G[SNMP Exporter]
G -->|指标数据| H[Prometheus]
end
H -->|拉取指标| E[Grafana]
本文所有说明建立在已有Prometheus+Grafana实例的基础上。
SNMP
SNMP(Simple Network Management Protocol,简单网络管理协议)是一种应用层协议,用于在IP网络中收集和组织信息,并用于网络设备的管理和监控。当前主要广泛应用的版本是SNMPv2c和SNMPv3,两者最大的区别应该是v2c还在用明文的社区字符串进行认证,而v3引入了更强的安全机制,包括用户认证和数据加密。当然接口流量这种数据,也不是特别敏感的信息,这里我们主要使用v2c。
我们这里主要讨论设备和接口层面的流量监控,不涉及SNMP Trap的告警相关内容。
配置设备SNMP
以H3C交换机为例,在设备上启用SNMP服务,并配置只读社区字符串:
1 | snmp-agent |
可选操作,通过ACL限制SNMP访问来源:
1 | acl number 2000 |
配置完成保存后,可以先提前测试一下设备是否正常响应SNMP请求,我这里使用Paessler SNMP Tester。
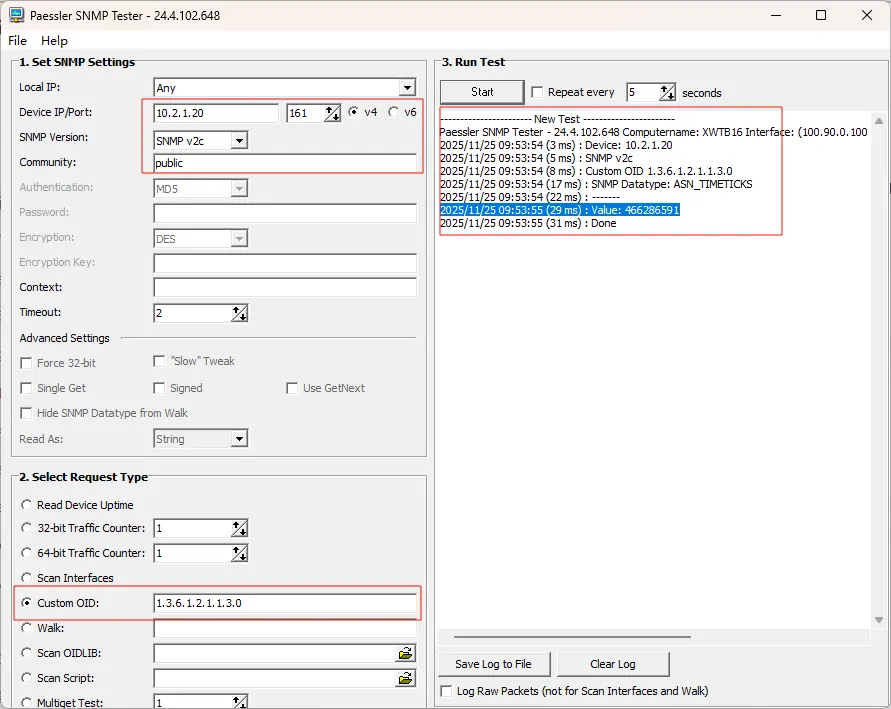
输入设备IP地址、端口(默认161)、版本(v2c)、社区字符串,测试用的OID可以使用公共的1.3.6.1.2.1.1.3.0(sysUpTime),如果能正常返回数据,说明SNMP配置成功。
关于sysUpTime和OID
关于上面使用的OID,是由RFC定义的公共标准,它具体的含义是
SNMP Agent 自上次启动以来的时间(单位TimeTicks,即1/100 秒),更多相关信息详见相关RFC文档。
| OID 段 | 名称 | 来源 |
|---|---|---|
.1 |
iso |
ISO/IEC |
.1.3 |
org |
ISO identified organization |
.1.3.6 |
dod |
US Department of Defense |
.1.3.6.1 |
internet |
RFC 1155 |
.1.3.6.1.2 |
mgmt |
RFC 1155 |
.1.3.6.1.2.1 |
mib-2 |
RFC 1213 |
.1.3.6.1.2.1.1 |
system |
RFC 1213 |
.1.3.6.1.2.1.1.3 |
sysUpTime |
RFC 1213 / RFC 3418 |
.1.3.6.1.2.1.1.3.0 |
实例(scalar object) | SNMP 规定标量对象必须加 .0 |
搭建Prometheus SNMP Exporter
官方提供二进制文件,这里用docker部署
1 | docker run -d \ |
对于大部分场景,官方默认使用的容器内配置文件/etc/snmp_exporter/snmp.yml是足够的,如果你有更复杂的需求,例如你的只读社区字符串不是public,可以挂载外部配置文件:
1 | -v <本地snmp.yml 配置文件>:/etc/snmp_exporter/snmp.yml \ |
如果你需要一些厂商特定的MIB支持,参考:
在Prometheus中配置SNMP抓取任务
在Prometheus的配置文件prometheus.yml中添加抓取任务:
1 | scrape_configs: |
因为不同设备的性能和活跃端口数量不同,更推荐的实践是根据不同种类的设备,建立多个job,分别配置一批targets,配置不同的scrape_interval和scrape_timeout,灵活调整抓取粒度。
对于module参数,如果只是用于抓取接口流量,if_mib模块已经足够。这里示例中的system模块用于抓取设备的系统信息,例如运行时间、设备名称等。详情请阅读默认的snmp.yml配置文件。
配置完成后,重启Prometheus服务或通过API热重载配置后在Status > Targets页面查看相关job抓取状态。
对于Grafana可视化设计,可以参考社区提供的SNMP Exporter,在其基础上根据实际需求进行调整。
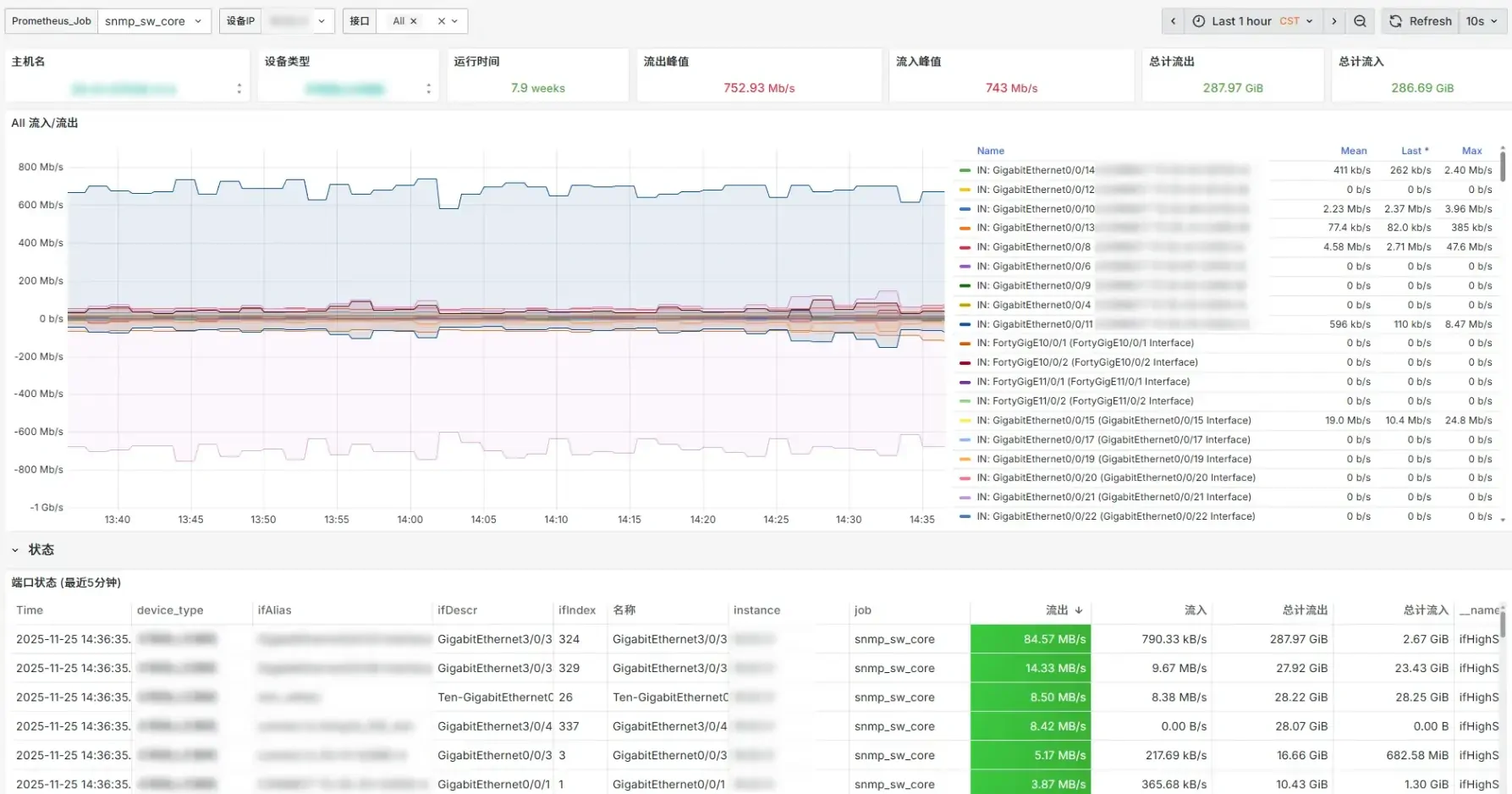
我这里正在使用的仅SNMP仪表盘大概是这样,其中主机名和运行时间是通过system模块抓取的,其余流量相关指标均来自if_mib模块,设备类型是Prometheus配置文件中通过targets的labels标签提前自定义的。
sFlow
sFlow是一种用于网络流量测量的协议,它允许设备(如交换机、路由器)以采样的方式将部分流量采集并传输给一个或多个收集器,从而通过收集器实现对网络流量的监控和分析。这里介绍的方案基于goflow2的kcg样例,为实际部署和长期使用优化。
配置设备sFlow采集
配置设备sFlow采集,具体操作请参考设备厂商的文档,这里以H3C交换机为例:
1 | # 全局配置 |
| 配置 | 关键字 | 说明 |
|---|---|---|
| sflow agent ip 10.0.0.1 | agent ip | 指定 sFlow Agent 的源 IP 地址,通常设置为设备的管理 IP。该地址用于标识数据来源,在收集器侧用于区分不同设备。 |
| sflow collector 1 ip 10.0.10.1 description “CLI Collector” | collector 1 | 定义一个编号为 1 的 sFlow 收集器(Collector)。 • ip 10.0.10.1:指定收集器服务器的 IP 地址。• description:可选描述信息,便于识别用途。 |
| sflow flow collector 1 | flow collector | 在接口下启用流量采样,并将采样数据发送到编号为 1 的收集器。必须先在全局定义该 collector。 |
| sflow sampling-rate 1000 | sampling-rate | 设置流量采样率。例如 1000 表示平均每 1000 个数据包采样 1 个(即采样比例 1/1000)。值越小采样越密集,对性能影响越大;值越大则数据越稀疏但更节省资源。 |
| sflow counter collector 1 | counter collector | 在接口下启用接口计数器统计(如入/出字节数、包数等),并将统计数据发送到编号为 1 的收集器。 |
| sflow counter interval 20 | counter interval | 设置接口计数器的上报间隔,单位为秒。例如 20 表示每 20 秒向收集器发送一次接口统计信息。H3C 默认通常为 30 秒,可按需调整。 |
- Agent IP 必须可达且稳定,一般使用管理 VLAN 接口 IP。
- Collector IP 需确保网络可达,且目标服务器(如 GoFlow2、sflowtool)正在监听 UDP 6343 端口(sFlow 默认端口)。
- 采样率 应根据网络带宽和监控精度需求权衡。
- 骨干链路(高吞吐): 1000~10000
- 计费统计或安全敏感场景:可设为 100 甚至更低(设为1则为全采样,但不推荐)
- Counter 与 Flow:
- Flow:基于采样的原始流记录(IP、端口、协议等),用于分析会话行为。
- Counter:接口级统计指标(如包数、字节数等),用于流量趋势分析.
sFlow的行为是基于采样的,而不是时间间隔,采样率(如 1:1000)表示:每 N 个数据包中,随机抽取 1 个进行采样,设备自身根据缓冲区使用情况或内部定时器触发向收集器发送样本,每个 sFlow Datagram(UDP 报文)可包含多个采样记录。
有的设备可能不支持太低的采样率,太低可能会影响设备性能,对于大部分的千兆链路,1000已经足够使用。
搭建GoFlow2
Cloudflare开源的GoFlow于2025年1月停止维护,GoFlow2是社区接手并持续更新的版本,支持包括NetFlow/IPFIX/sFlow在内的多种流量采集协议,你可以先使用官方的二进制文件在目标服务器上尝试运行:
1 | ./goflow2 |
其默认行为是在6343端口监听sFlow协议,在2055端口监听NetFlow/IPFIX协议,并将收集到的报文以JSON格式打印到控制台。借此来验证我们的设备配置是否正确。
对于最终的部署,依然使用Docker运行:
1 | docker run -d \ |
-transport.kafka.brokers指定接下来要搭建的Kafka集群地址,-transport=kafka指定使用Kafka作为数据传输方式,-transport.kafka.topic指定Kafka的Topic名称,-format=bin指定数据格式为二进制。
此外,如果你不是单机部署,有额外独立的Kafka集群,那你可以考虑使用-transport.kafka.compression.type=gzip来启用压缩功能。
如果单机部署,可以考虑将-transport.kafka.brokers=10.0.10.1:9092这种直接指向本机ip的方式改为Docker自定义网络、使用host.docker.internal或Docker Compose的network_mode: host来指向宿主机ip。
运行后你可以访问http://<采集主机地址>:8080/metrics大概查看GoFlow2拿到的数据,推荐搜索agent=关键字来查看已接入的设备。
搭建Kafka
Kafka作为中间件,在系统之间可靠、高效地传输和处理实时数据流,在这里用于解耦生产者(GoFlow2)和消费者(ClickHouse),为数据库做数据缓冲与削峰填谷。
如果有类似Paas的平台,最好使用此类现有的Kafka集群,本例我们使用单容器来运行一个同时承担Broker和Controller的角色的Kafka实例:
1 | docker run -d \ |
搭建ClickHouse
本例中,假设将ClickHouse相关目录映射至/home/user/app/clickhouse,在该目录下,准备三个文件:
init/create.sh数据库初始化脚本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
set -e
clickhouse client -n <<-EOSQL
CREATE DATABASE IF NOT EXISTS dictionaries;
CREATE DICTIONARY IF NOT EXISTS dictionaries.protocols (
proto UInt8,
name String,
description String
)
PRIMARY KEY proto
LAYOUT(FLAT())
SOURCE (FILE(path '/var/lib/clickhouse/user_files/protocols.csv' format 'CSVWithNames'))
LIFETIME(3600);
CREATE TABLE IF NOT EXISTS flows
(
time_received_ns UInt64,
time_flow_start_ns UInt64,
sequence_num UInt32,
sampling_rate UInt64,
sampler_address FixedString(16),
src_addr FixedString(16),
dst_addr FixedString(16),
src_as UInt32,
dst_as UInt32,
etype UInt32,
proto UInt32,
src_port UInt32,
dst_port UInt32,
bytes UInt64,
packets UInt64
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = '10.2.11.40:9092',
kafka_num_consumers = 1,
kafka_topic_list = 'flows',
kafka_group_name = 'clickhouse',
kafka_format = 'Protobuf',
kafka_schema = 'flow.proto:FlowMessage';
CREATE TABLE IF NOT EXISTS flows_raw
(
date Date,
time_inserted_ns DateTime64(9),
time_received_ns DateTime64(9),
time_flow_start_ns DateTime64(9),
sequence_num UInt32,
sampling_rate UInt64,
sampler_address FixedString(16),
src_addr FixedString(16),
dst_addr FixedString(16),
src_as UInt32,
dst_as UInt32,
etype UInt32,
proto UInt32,
src_port UInt32,
dst_port UInt32,
bytes UInt64,
packets UInt64
) ENGINE = MergeTree()
PARTITION BY date
ORDER BY time_received_ns;
TTL date + INTERVAL 30 DAY; -- 保留30天原始数据
CREATE MATERIALIZED VIEW IF NOT EXISTS flows_raw_view TO flows_raw
AS SELECT
toDate(time_received_ns) AS date,
now() AS time_inserted_ns,
toDateTime64(time_received_ns/1000000000, 9) AS time_received_ns,
toDateTime64(time_flow_start_ns/1000000000, 9) AS time_flow_start_ns,
sequence_num,
sampling_rate,
sampler_address,
src_addr,
dst_addr,
src_as,
dst_as,
etype,
proto,
src_port,
dst_port,
bytes,
packets
FROM flows;
CREATE TABLE IF NOT EXISTS flows_5m
(
date Date,
timeslot DateTime,
src_as UInt32,
dst_as UInt32,
etypeMap Nested (
etype UInt32,
bytes UInt64,
packets UInt64,
count UInt64
),
bytes UInt64,
packets UInt64,
count UInt64
) ENGINE = SummingMergeTree()
PARTITION BY date
ORDER BY (date, timeslot, src_as, dst_as, \`etypeMap.etype\`);
TTL date + INTERVAL 30 DAY; -- 保留30天聚合数据
CREATE MATERIALIZED VIEW IF NOT EXISTS flows_5m_view TO flows_5m
AS
SELECT
date,
toStartOfFiveMinute(time_received_ns) AS timeslot,
src_as,
dst_as,
[etype] AS \`etypeMap.etype\`,
[bytes] AS \`etypeMap.bytes\`,
[packets] AS \`etypeMap.packets\`,
[count] AS \`etypeMap.count\`,
sum(bytes) AS bytes,
sum(packets) AS packets,
count() AS count
FROM flows_raw
GROUP BY date, timeslot, src_as, dst_as, \`etypeMap.etype\`;
EOSQL数据库初始化脚本中43行处,
kafka_broker_list = '10.0.10.1:9092'用于指定目标Kafka实例,kafka_topic_list = 'flows'用于指定ClickHouse数据库要消费的Kafka主题,此处为我们在创建Kafka实例时使用的Topicflows。flows_raw和flows_5m是数据表,默认为其配置数据生存时间30天,通过DDL语句中的TTL设置,此值对存储空间有较大影响,请按实际需求配置。
该初始化脚本定义的对象如下:
| 名称 | 类型 | 引擎 / 用途 | 数据来源 / 写入方式 | TTL(数据保留时间) | 主要用途说明 |
|---|---|---|---|---|---|
dictionaries.protocols |
字典(Dictionary) | FLAT() 布局,从 CSV 文件加载 |
/var/lib/clickhouse/user_files/protocols.csv |
LIFETIME(3600)(字典多久从源重新加载一次) |
协议编号 → 名称/描述 的映射 |
flows |
Kafka 消费表 | Kafka() 引擎 |
从 Kafka topic flows 消费 Protobuf 格式消息 |
无(仅管道,不存数据) | 实时流数据接入入口 |
flows_raw |
数据表 | MergeTree() |
由物化视图 flows_raw_view 自动写入 |
date + INTERVAL 30 DAY |
存储原始 NetFlow/sFlow 记录,按天分区 |
flows_raw_view |
物化视图 | (写入 flows_raw) |
监听 flows 表的 INSERT,转换后写入 flows_raw |
- | 自动将 Kafka 消息转为结构化原始记录 |
flows_5m |
数据表 | SummingMergeTree() |
由物化视图 flows_5m_view 自动写入 |
date + INTERVAL 30 DAY |
按 5 分钟粒度聚合流量统计 |
flows_5m_view |
物化视图 | (写入 flows_5m) |
监听 flows_raw 表的 INSERT,聚合后写入 flows_5m |
- | 自动生成 5 分钟级聚合指标 |
在 ClickHouse 中,物化视图本质上就是一个“自动写入规则”,或者理解为一个隐式的“INSERT”触发器,它定义了当源表插入新数据时,如何转换这些数据,并自动写入到另一个目标表中。
flow.protoClickHouse的Protobuf格式定义文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123syntax = "proto3";
package flowpb;
option go_package = "github.com/netsampler/goflow2/pb;flowpb";
message FlowMessage {
enum FlowType {
FLOWUNKNOWN = 0;
SFLOW_5 = 1;
NETFLOW_V5 = 2;
NETFLOW_V9 = 3;
IPFIX = 4;
}
FlowType type = 1;
uint64 time_received_ns = 110;
uint32 sequence_num = 4;
uint64 sampling_rate = 3;
//uint32 flow_direction = 42;
// Sampler information
bytes sampler_address = 11;
// Found inside packet
uint64 time_flow_start_ns = 111;
uint64 time_flow_end_ns = 112;
// Size of the sampled packet
uint64 bytes = 9;
uint64 packets = 10;
// Source/destination addresses
bytes src_addr = 6;
bytes dst_addr = 7;
// Layer 3 protocol (IPv4/IPv6/ARP/MPLS...)
uint32 etype = 30;
// Layer 4 protocol
uint32 proto = 20;
// Ports for UDP and TCP
uint32 src_port = 21;
uint32 dst_port = 22;
// Interfaces
uint32 in_if = 18;
uint32 out_if = 19;
// Ethernet information
uint64 src_mac = 27;
uint64 dst_mac = 28;
// Vlan
uint32 src_vlan = 33;
uint32 dst_vlan = 34;
// 802.1q VLAN in sampled packet
uint32 vlan_id = 29;
// IP and TCP special flags
uint32 ip_tos = 23;
uint32 forwarding_status = 24;
uint32 ip_ttl = 25;
uint32 ip_flags = 38;
uint32 tcp_flags = 26;
uint32 icmp_type = 31;
uint32 icmp_code = 32;
uint32 ipv6_flow_label = 37;
// Fragments (IPv4/IPv6)
uint32 fragment_id = 35;
uint32 fragment_offset = 36;
// Autonomous system information
uint32 src_as = 14;
uint32 dst_as = 15;
bytes next_hop = 12;
uint32 next_hop_as = 13;
// Prefix size
uint32 src_net = 16;
uint32 dst_net = 17;
// BGP information
bytes bgp_next_hop = 100;
repeated uint32 bgp_communities = 101;
repeated uint32 as_path = 102;
// MPLS information
repeated uint32 mpls_ttl = 80;
repeated uint32 mpls_label = 81;
repeated bytes mpls_ip = 82;
uint32 observation_domain_id = 70;
uint32 observation_point_id = 71;
// Encapsulation
enum LayerStack {
Ethernet = 0;
IPv4 = 1;
IPv6 = 2;
TCP = 3;
UDP = 4;
MPLS = 5;
Dot1Q = 6;
ICMP = 7;
ICMPv6 = 8;
GRE = 9;
IPv6HeaderRouting = 10;
IPv6HeaderFragment = 11;
Geneve = 12;
Teredo = 13;
Custom = 99;
// todo: add nsh
}
repeated LayerStack layer_stack = 103;
repeated uint32 layer_size = 104;
repeated bytes ipv6_routing_header_addresses = 105; // SRv6
uint32 ipv6_routing_header_seg_left = 106; // SRv6
}protocols.csv网络协议定义文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30proto,name,description
0,HOPOPT,IPv6 Hop-by-Hop Option
1,ICMP,Internet Control Message
2,IGMP,Internet Group Management
4,IPv4,IPv4 encapsulation
6,TCP,Transmission Control Protocol
8,EGP,Exterior Gateway Protocol
9,IGP,Interior Gateway Protocol
16,CHAOS,Chaos
17,UDP,User Datagram Protocol
27,RDP,Reliable Data Protocol
41,IPv6,IPv6 encapsulation
43,IPv6-Route,Routing Header for IPv6
44,IPv6-Frag,Fragment Header for IPv6
45,IDRP,Inter-Domain Routing Protocol
46,RSVP,Reservation Protocol
47,GRE,Generic Routing Encapsulation
50,ESP,Encap Security Payload
51,AH,Authentication Header
55,MOBILE,IP Mobility
58,IPv6-ICMP,ICMP for IPv6
59,IPv6-NoNxt,No Next Header for IPv6
60,IPv6-Opts,Destination Options for IPv6
88,EIGRP,EIGRP
89,OSPFIGP,OSPFIGP
92,MTP,Multicast Transport Protocol
94,IPIP,IP-within-IP Encapsulation Protocol
97,ETHERIP,Ethernet-within-IP Encapsulation
98,ENCAP,Encapsulation Header
112,VRRP,Virtual Router Redundancy Protocol
总体的处理流程如下:
flowchart LR
A[Kafka MQ<br>Topic flows] -->|Protobuf| B[Kafka<br>flows]
subgraph ClickHouse
B -->|数据转换| C[物化视图<br>flows_raw_view]
C -->|写入| D[MergeTree<br>flows_raw]
D -->|5min<br>聚合| E[物化视图<br>flows_5m_view]
E -->|写入| F[SummingMergeTree<br>flows_5m]
end
使用Docker启动ClickHouse服务:
1 | docker run -d |
运行后可以通过http://ip:8123进入ClickHouse自带的一个管理界面,可以通过Web SQL UI连接到实例,并查看初始化脚本是否应用成功: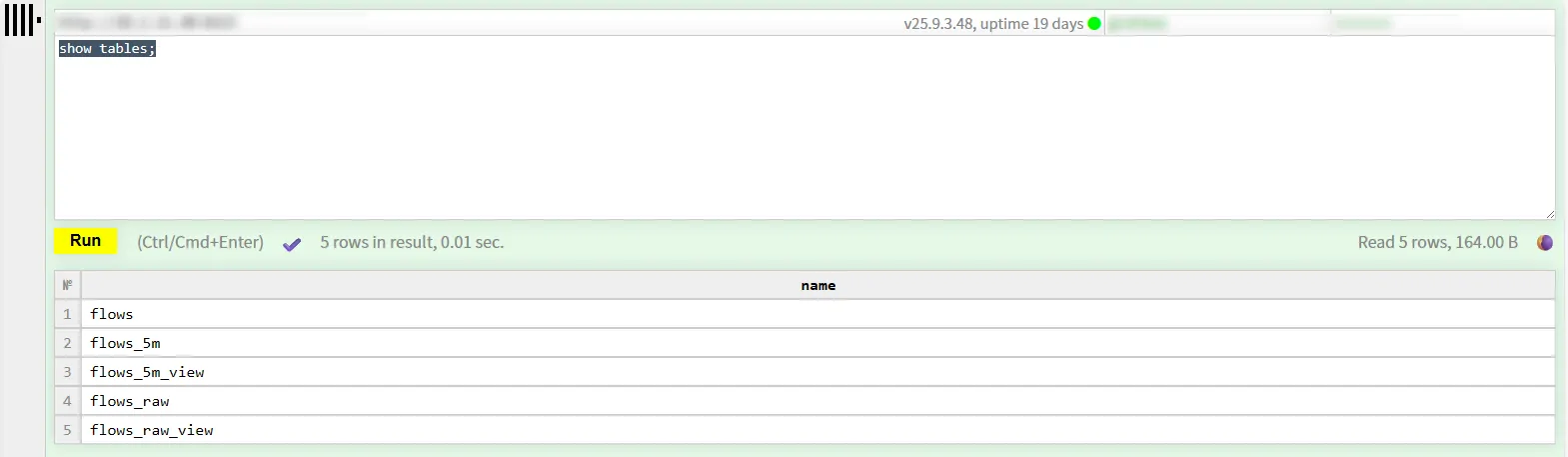
顺带一提,如果你要在ClickHouse中直接查询IP相关的列,你会得到乱码: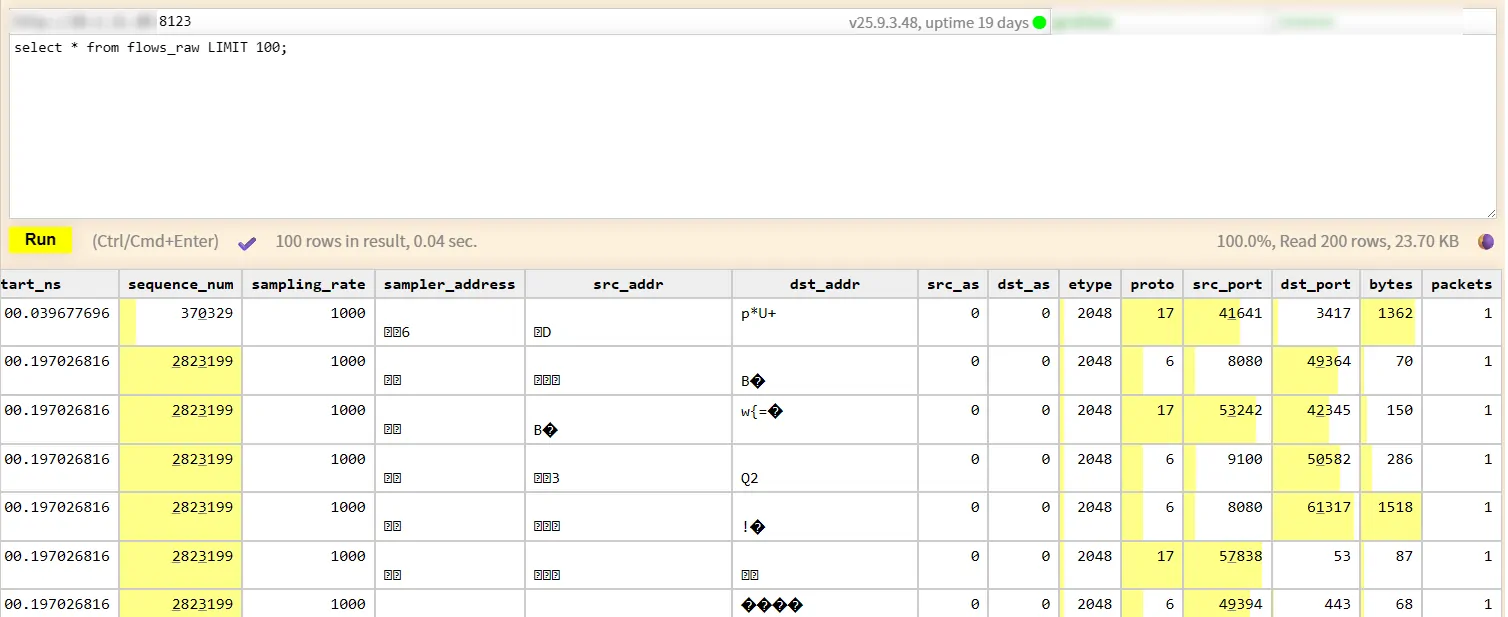
原因是地址以 FixedString(16) 的形式插入到 Clickhouse 中,因为要兼容有IPv6的情况。在存储IPv4地址时实际上只是 IPv4 的 4 个字节,示例的查询语句是:
1 | if(EType = 0x800, IPv4NumToString(reinterpretAsUInt32(substring(reverse(SrcAddr), 13,4))), IPv6NumToString(SrcAddr)) |
网络传输中使用的字节序是大端序(Big-endian),即高位字节存储在低内存地址。通过reverse函数将地址按字节反转,然后通过截取最后的4个字节,即可获取目标IPv4地址。
Grafana数据源
对于SNMP,Grafana可以从Prometheus直接获取数据,对于sFlow,需要对Grafana安装ClickHouse数据源插件,这里使用Altinity plugin for ClickHouse,安装后直接添加数据源即可:
GoFlow2项目中提供了一个简单的Dashboard示例,可在此基础上构建面板,无非就是搓一些SQL,这个看实际需求了。
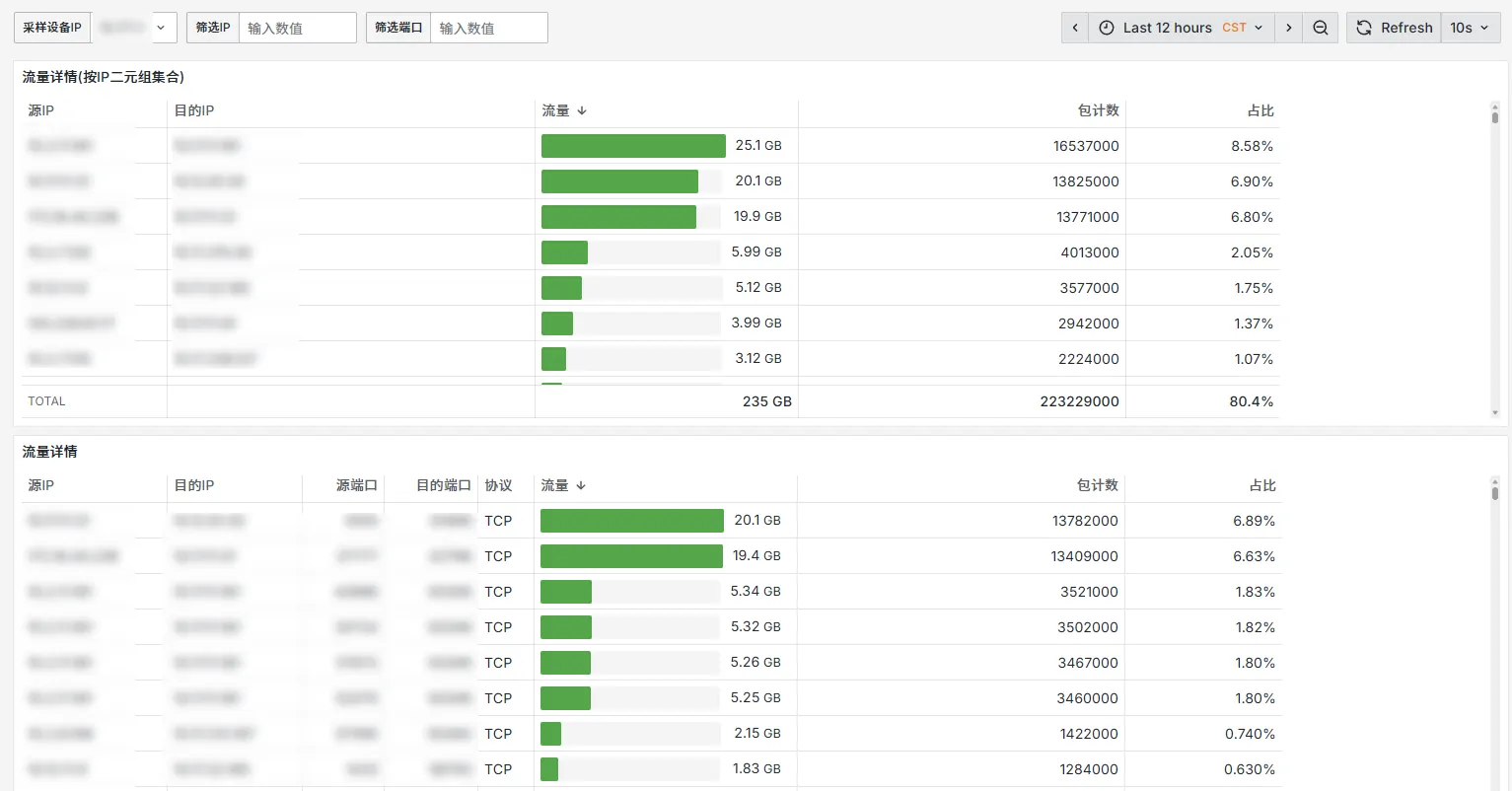
Ending
需要明确的一点是,sFlow是一个基于随机采样的协议,即它是通过局部数据包的采样来反映整体流量状态,具体精确度取决于你的采样率配置。sFlow能满足流量趋势审计、性能评估等方面的需求,但不适合流量计费、安全取证与分析、低流量或低频流应用。上述数据处理流程中,”流量”、”包计数”等值都是基于采样包参数*采样率 这样的测算方式得到的,可能与真实的业务流量存在差异,但能反映总体趋势,解决类似”谁访问谁造成了比较大的带宽占用”、”哪个服务哪个端口占用了更多的带宽”等问题。可视化角度上,可以融合SNMP和sFlow数据到一个Dashboard,从多个角度提供研判数据。
 wechat
wechat- alipay





